
1. Giriş
Bugün, ekonomik eğitim ve verimli çıkarım özellikleriyle öne çıkan güçlü bir Uzmanlar Karışımı (Mixture-of-Experts – MoE) dil modeli olan DeepSeek-V2’yi tanıtıyoruz. Toplamda 236 milyar parametreye sahip olup, her bir token için 21 milyar parametre etkinleştirilmektedir. DeepSeek 67B ile karşılaştırıldığında, DeepSeek-V2 daha güçlü bir performans sunarken, eğitim maliyetlerinde %42,5 tasarruf sağlar, KV önbelleğini %93,3 oranında azaltır ve maksimum üretim verimini 5,76 kat artırır.

DeepSeek-V2’yi, 8,1 trilyon token’dan oluşan çeşitli ve yüksek kaliteli bir veri kümesi üzerinde önceden eğittik. Bu kapsamlı ön eğitim sürecinin ardından, modelin yeteneklerini tam anlamıyla ortaya çıkarmak için Denetimli İnce Ayar (Supervised Fine-Tuning – SFT) ve Pekiştirmeli Öğrenme (Reinforcement Learning – RL) aşamalarını uyguladık. Değerlendirme sonuçları, DeepSeek-V2’nin hem standart testlerde hem de açık uçlu üretim değerlendirmelerinde kayda değer bir performans sergilediğini doğrulamaktadır.

2. Haberler
- 2024.05.16: DeepSeek-V2-Lite’ı yayınladık.
- 2024.05.06: DeepSeek-V2’yi yayınladık.
3. Model İndirmeleri
| Model | Toplam Parametre Sayısı | Etkin Parametre Sayısı | Bağlam Uzunluğu | İndirme Linki |
|---|---|---|---|---|
| DeepSeek-V2-Lite | 16B | 2.4B | 32k | 🤗 HuggingFace |
| DeepSeek-V2-Lite-Chat (SFT) | 16B | 2.4B | 32k | 🤗 HuggingFace |
| DeepSeek-V2 | 236B | 21B | 128k | 🤗 HuggingFace |
| DeepSeek-V2-Chat (RL) | 236B | 21B | 128k | 🤗 HuggingFace |
Not: HuggingFace’in kısıtlamaları nedeniyle, açık kaynak kodumuz şu anda GPU’larda HuggingFace ile çalışırken dahili kod tabanımıza göre daha yavaş performans göstermektedir. Modelimizin verimli bir şekilde çalıştırılmasını kolaylaştırmak için, performansı optimize eden özel bir vllm çözümü sunuyoruz.
4. Değerlendirme Sonuçları
Temel Model
Standart Benchmark (67B’den büyük modeller)
| Benchmark | Domain | LLaMA3 70B | Mixtral 8x22B | DeepSeek-V1 (Dense-67B) | DeepSeek-V2 (MoE-236B) |
|---|---|---|---|---|---|
| MMLU | English | 78.9 | 77.6 | 71.3 | 78.5 |
| BBH | English | 81.0 | 78.9 | 68.7 | 78.9 |
| C-Eval | Chinese | 67.5 | 58.6 | 66.1 | 81.7 |
| CMMLU | Chinese | 69.3 | 60.0 | 70.8 | 84.0 |
| HumanEval | Code | 48.2 | 53.1 | 45.1 | 48.8 |
| MBPP | Code | 68.6 | 64.2 | 57.4 | 66.6 |
| GSM8K | Math | 83.0 | 80.3 | 63.4 | 79.2 |
| Math | Math | 42.2 | 42.5 | 18.7 | 43.6 |
Standart Benchmark (16B’den küçük modeller)
| Benchmark | Domain | DeepSeek 7B (Dense) | DeepSeekMoE 16B | DeepSeek-V2-Lite (MoE-16B) |
|---|---|---|---|---|
| Architecture | – | MHA+Dense | MHA+MoE | MLA+MoE |
| MMLU | English | 48.2 | 45.0 | 58.3 |
| BBH | English | 39.5 | 38.9 | 44.1 |
| C-Eval | Chinese | 45.0 | 40.6 | 60.3 |
| CMMLU | Chinese | 47.2 | 42.5 | 64.3 |
| HumanEval | Code | 26.2 | 26.8 | 29.9 |
| MBPP | Code | 39.0 | 39.2 | 43.2 |
| GSM8K | Math | 17.4 | 18.8 | 41.1 |
| Math | Math | 3.3 | 4.3 | 17.1 |
Az çekim ayarları ve uyarılar gibi daha fazla değerlendirme ayrıntısı için lütfen makalemizi inceleyin.
Bağlam Penceresi
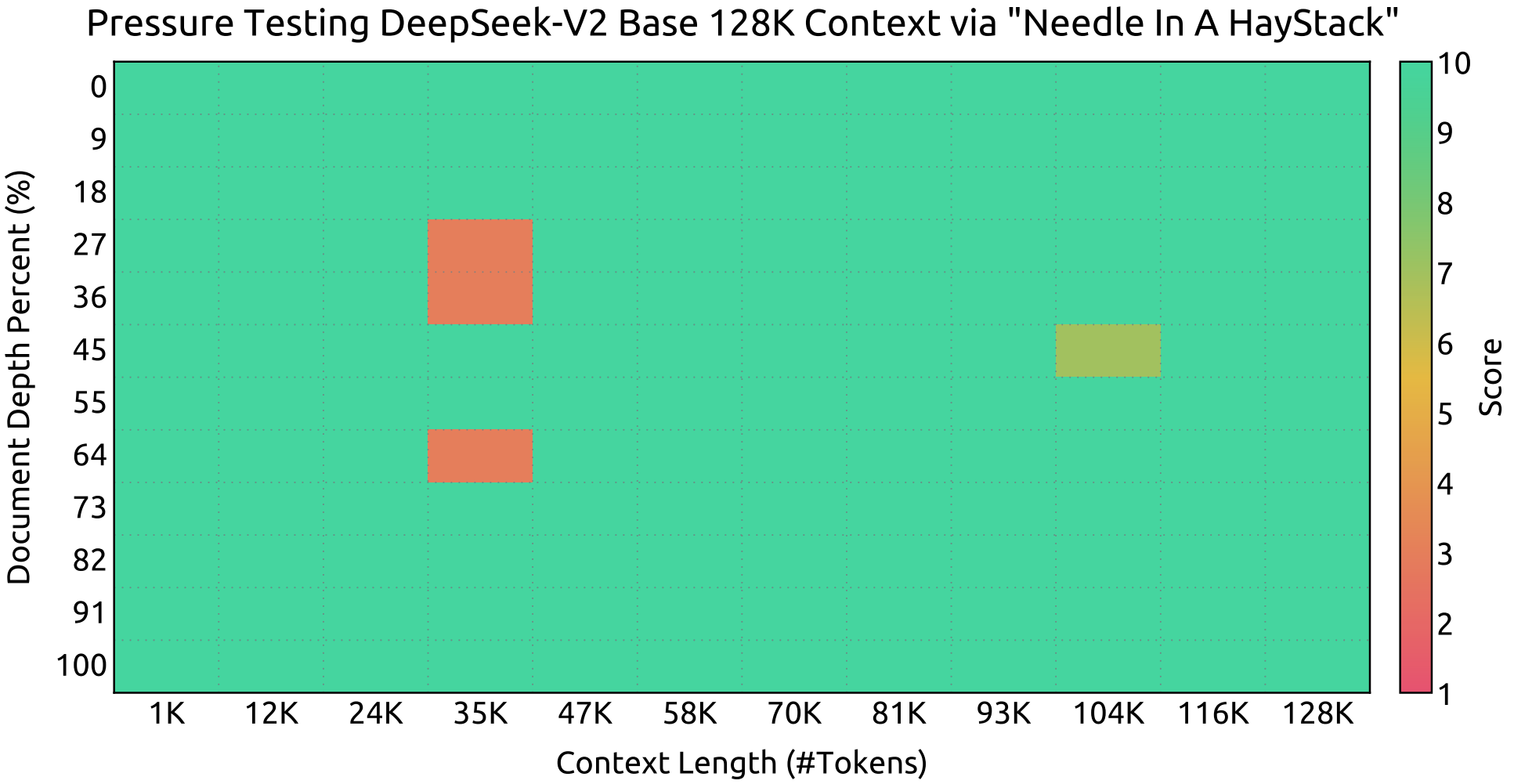
Needle In A Haystack (NIAH) testlerindeki değerlendirme sonuçları. DeepSeek-V2, 128K’ya kadar tüm bağlam penceresi uzunluklarında iyi performans gösterir.
Sohbet Modeli
Standart Ölçüt (67B’den büyük modeller)
| Benchmark | Domain | QWen1.5 72B Chat | Mixtral 8x22B | LLaMA3 70B Instruct | DeepSeek-V1 Chat (SFT) | DeepSeek-V2 Chat (SFT) | DeepSeek-V2 Chat (RL) |
|---|---|---|---|---|---|---|---|
| MMLU | English | 76.2 | 77.8 | 80.3 | 71.1 | 78.4 | 77.8 |
| BBH | English | 65.9 | 78.4 | 80.1 | 71.7 | 81.3 | 79.7 |
| C-Eval | Chinese | 82.2 | 60.0 | 67.9 | 65.2 | 80.9 | 78.0 |
| CMMLU | Chinese | 82.9 | 61.0 | 70.7 | 67.8 | 82.4 | 81.6 |
| HumanEval | Code | 68.9 | 75.0 | 76.2 | 73.8 | 76.8 | 81.1 |
| MBPP | Code | 52.2 | 64.4 | 69.8 | 61.4 | 70.4 | 72.0 |
| LiveCodeBench (0901-0401) | Code | 18.8 | 25.0 | 30.5 | 18.3 | 28.7 | 32.5 |
| GSM8K | Math | 81.9 | 87.9 | 93.2 | 84.1 | 90.8 | 92.2 |
| Math | Math | 40.6 | 49.8 | 48.5 | 32.6 | 52.7 | 53.9 |
Standart Ölçüt (16B’den küçük modeller)
| Benchmark | Domain | DeepSeek 7B Chat (SFT) | DeepSeekMoE 16B Chat (SFT) | DeepSeek-V2-Lite 16B Chat (SFT) |
|---|---|---|---|---|
| MMLU | English | 49.7 | 47.2 | 55.7 |
| BBH | English | 43.1 | 42.2 | 48.1 |
| C-Eval | Chinese | 44.7 | 40.0 | 60.1 |
| CMMLU | Chinese | 51.2 | 49.3 | 62.5 |
| HumanEval | Code | 45.1 | 45.7 | 57.3 |
| MBPP | Code | 39.0 | 46.2 | 45.8 |
| GSM8K | Math | 62.6 | 62.2 | 72.0 |
| Math | Math | 14.7 | 15.2 | 27.9 |
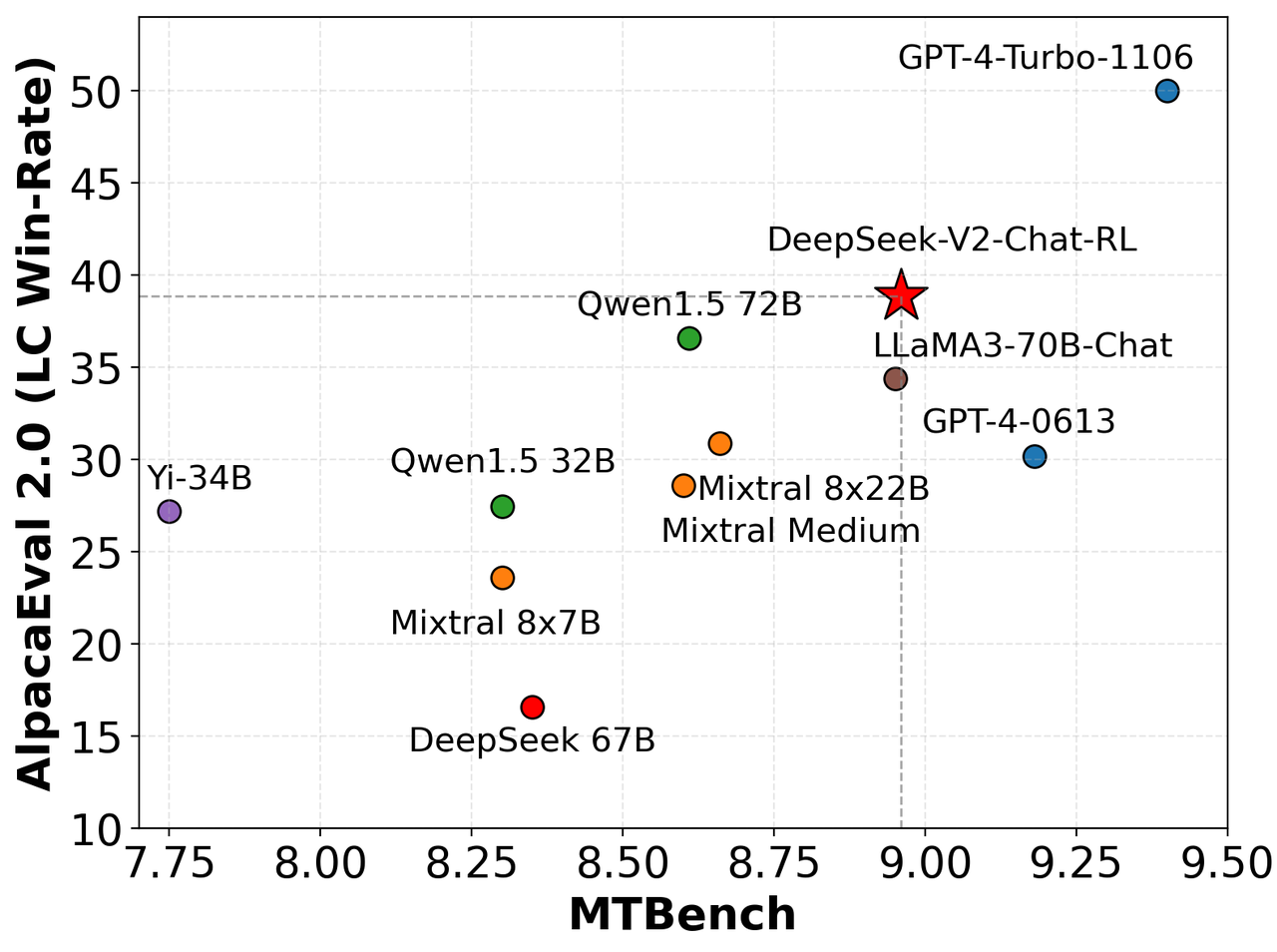
İngilizce Açık Uçlu Üretim Değerlendirmesi
Modelimizi AlpacaEval 2.0 ve MTBench üzerinde değerlendiriyoruz ve DeepSeek-V2-Chat-RL’nin İngilizce konuşma üretimi üzerindeki rekabetçi performansını gösteriyoruz.
Çince Açık Uçlu Nesil Değerlendirmesi
| 模型 | 开源/闭源 | 总分 | 中文推理 | 中文语言 |
|---|---|---|---|---|
| gpt-4-1106-preview | 闭源 | 8.01 | 7.73 | 8.29 |
| DeepSeek-V2 Chat (RL) | 开源 | 7.91 | 7.45 | 8.36 |
| erniebot-4.0-202404 (文心一言) | 闭源 | 7.89 | 7.61 | 8.17 |
| DeepSeek-V2 Chat (SFT) | 开源 | 7.74 | 7.30 | 8.17 |
| gpt-4-0613 | 闭源 | 7.53 | 7.47 | 7.59 |
| erniebot-4.0-202312 (文心一言) | 闭源 | 7.36 | 6.84 | 7.88 |
| moonshot-v1-32k-202404 (月之暗面) | 闭源 | 7.22 | 6.42 | 8.02 |
| Qwen1.5-72B-Chat (通义千问) | 开源 | 7.19 | 6.45 | 7.93 |
| DeepSeek-67B-Chat | 开源 | 6.43 | 5.75 | 7.11 |
| Yi-34B-Chat (零一万物) | 开源 | 6.12 | 4.86 | 7.38 |
| gpt-3.5-turbo-0613 | 闭源 | 6.08 | 5.35 | 6.71 |
| DeepSeek-V2-Lite 16B Chat | 开源 | 6.01 | 4.71 | 7.32 |
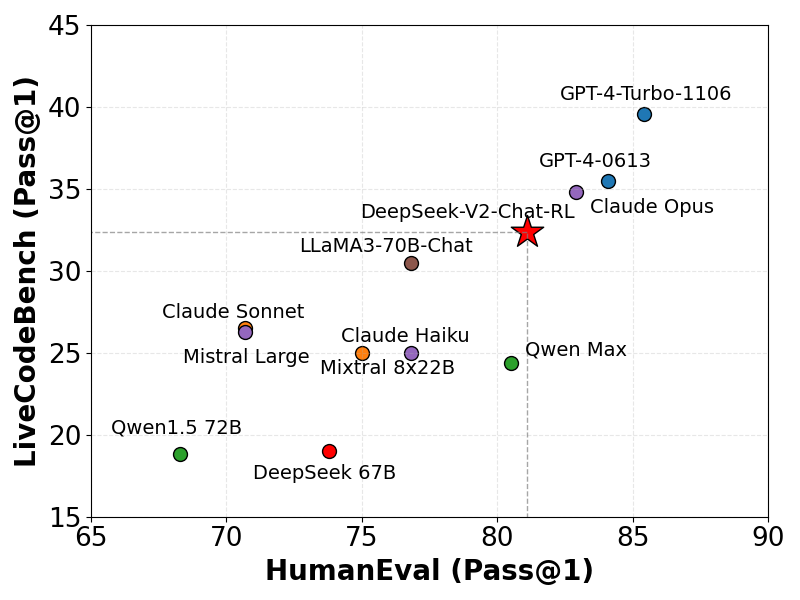
Kodlama Ölçütleri
Modelimizi canlı kodlama zorlukları için tasarlanmış bir ölçüt olan LiveCodeBench’te (0901-0401) değerlendiriyoruz. Gösterildiği gibi, DeepSeek-V2, LiveCodeBench’te önemli bir yeterlilik göstererek, diğer birkaç gelişmiş modeli geride bırakan bir Pass@1 puanı elde ediyor. Bu performans, modelin canlı kodlama görevlerini ele almadaki etkinliğini vurguluyor.
5. Model Mimarisi
DeepSeek-V2, ekonomik eğitim ve verimli çıkarım sağlamak için yenilikçi mimarileri benimsemektedir:
-
Dikkat Mekanizması (Attention):
MLA (Multi-head Latent Attention) tasarımı, düşük dereceli anahtar-değer birleştirme sıkıştırması kullanarak çıkarım sırasında KV önbelleği darboğazlarını ortadan kaldırır. Bu sayede, model daha hızlı ve verimli çıkarım yapabilir. -
İleri Beslemeli Ağlar (Feed-Forward Networks – FFNs):
DeepSeekMoE mimarisi, yüksek performanslı bir MoE (Mixture-of-Experts) yaklaşımı benimseyerek daha güçlü modellerin düşük maliyetle eğitilmesini mümkün kılar.
6. Sohbet Web Sitesi
DeepSeek-V2 ile DeepSeek’in resmi web sitesinde sohbet edebilirsiniz: chat.deepseek.com
7. API Platformu
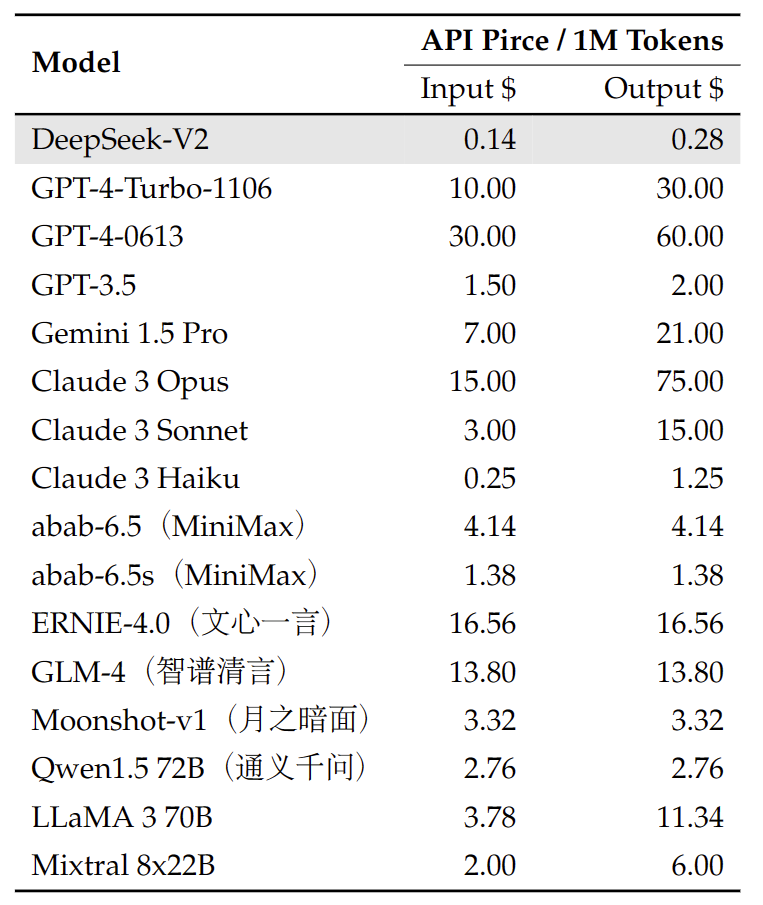
DeepSeek Platformunda OpenAI Uyumlu API de sağlıyoruz: platform.deepseek.com. Milyonlarca ücretsiz token için kaydolun. Ayrıca rakipsiz bir fiyata ödedikçe kullanabilirsiniz.
8. İletişim
Herhangi bir sorunuz varsa lütfen bir sorun bildirin veya service@deepseekturkce.com adresinden bizimle iletişime geçin.